


Entenda como medir e monitorar o response time utilizando OpenTelemetry, Prometheus e Grafana no .NET. Descubra como identificar gargalos críticos, otimizar a experiência do usuário e transformar métricas em insights estratégicos para resultados de alto impacto.
O tempo de resposta é uma das métricas mais críticas para qualquer aplicação. Ele reflete o impacto direto na experiência do usuário e nos resultados de negócio. Entretanto, medir o tempo de resposta de forma global é um erro comum. Para análises precisas, precisamos segmentar e monitorar endpoints ou conjuntos de URLs que representem jornadas específicas do cliente, como login, busca de produtos e checkout.
Insights
- Métricas generalizadas não capturam problemas críticos. A análise detalhada por endpoint é indispensável para identificar e corrigir gargalos que afetam a experiência do usuário.
- Percentis como o P99 oferecem uma visão mais clara das latências extremas do sistema, destacando os momentos mais críticos ignorados pela média.
- Monitorar good requests e bad requests permite categorizar o desempenho e priorizar ações em situações onde os tempos de resposta ultrapassam o limite aceitável.
Por que medir o tempo de resposta por endpoint?
Quando o tempo de resposta é medido de forma agregada, detalhes importantes passam despercebidos. Por exemplo, em um e-commerce, o tempo médio pode parecer aceitável, mas se não analisarmos individualmente as requisições para o endpoint de checkout ou para as APIs de pagamento, gargalos críticos podem comprometer toda a experiência do cliente.
Medir por endpoints e associá-los às jornadas dos usuários permite detectar problemas de maneira assertiva. Imagine que o tempo de resposta da busca de produtos esteja bom, mas o carregamento do carrinho apresente latências devido a uma integração com uma API externa para cálculo de frete. Sem segmentação, esses problemas não seriam detectados até que o impacto fosse evidente nos resultados.
Medir o Response Time exige a métrica certa. Utilizar percentil é mais eficaz que média
Ao monitorar o tempo de resposta, muitas equipes caem na armadilha de confiar exclusivamente na média (average, ou avg) como métrica principal. Contudo, esta abordagem pode mascarar os problemas mais críticos enfrentados pelos usuários. A média é sensível a outliers, o que significa que tempos de resposta extremamente altos ou baixos distorcem o valor real e comprometem a análise de desempenho.
Como a média funciona e por que ela é limitada
A média é calculada somando-se os tempos de resposta de todas as requisições e dividindo o resultado pelo número total de requisições. Essa abordagem cria um valor único que representa o comportamento geral do sistema. Em um cenário ideal, onde os tempos de resposta são consistentemente distribuídos, a média seria uma métrica razoável.
No entanto, a realidade das aplicações modernas é muito mais complexa. Em sistemas distribuídos, especialmente aqueles que utilizam microsserviços e dependências externas, os tempos de resposta tendem a variar consideravelmente. Outliers, como uma requisição que demora 10 segundos em um conjunto onde a maioria é concluída em 500ms, têm um impacto desproporcional na média. Essa influência distorce a percepção de desempenho e pode levar a decisões equivocadas
Por exemplo, imagine uma API com os seguintes tempos de resposta para cinco requisições: 100ms, 200ms, 150ms, 180ms e 3000ms. A média seria calculada como: média = (100 + 200 + 150 + 180 + 3000) / 5 = 726ms
Como o percentil funciona e por que ele é mais confiável
O percentil, no caso P99, por outro lado, mede o desempenho das requisições mais lentas em um sistema. Ele ordena todas as requisições por tempo de resposta e identifica o valor no qual 99% das requisições foram concluídas. Isso significa que apenas 1% das requisições mais lentas estão fora do escopo do P99, permitindo que as equipes foquem em otimizar os casos mais críticos.
Usando o mesmo exemplo da API, os tempos de resposta ordenados seriam: 100ms, 150ms, 180ms, 200ms e 3000ms. O P99 neste caso é 3000ms, porque 99% das requisições estão abaixo desse valor (considerando um conjunto maior de dados). Isso expõe a requisição mais lenta como um ponto de atenção crítica. A análise baseada em percentis como o P99 é particularmente útil em sistemas que processam um grande volume de requisições, como e-commerces.
Enquanto a média tenta oferecer um panorama geral, o P99 aponta diretamente para os gargalos que causam experiências ruins aos usuários.
A escolha errada da métrica pode custar caro
Utilizar métricas inadequadas para medir o tempo de resposta pode levar a análises incompletas, dificultando a identificação de gargalos críticos e comprometendo a capacidade de melhorar o desempenho do sistema. m sistema com uma média aparentemente aceitável pode esconder picos de latência que afetam diretamente a experiência do usuário, resultando em abandonos e insatisfação.
Tempos de resposta elevados em etapas da jornada de um usuário – como login, busca de informações ou finalização de uma transação – são suficientes para comprometer a experiência e frustrar os clientes. A lentidão no sistema prejudica a percepção de qualidade, reduz a confiança dos usuários e, em muitos casos, resulta em perda de oportunidades e receitas.
Monitorar o sistema com foco em percentis como P99 é indispensável para capturar os momentos de pior desempenho e garantir que o sistema permaneça responsivo mesmo sob carga elevada. Essa abordagem permite que as empresas previnam problemas antes que eles afetem os resultados de maneira irreversível.
A importância de combinar P99 com outras métricas
Embora o P99 seja uma métrica poderosa, ele não deve ser analisado isoladamente. Combinar percentis com métricas como a média e o P95 oferece uma visão mais ampla do comportamento do sistema. A média ajuda a monitorar o desempenho geral, enquanto percentis como P99 e P95 destacam extremos que podem ser problemáticos.
Além disso, monitorar o histórico dessas métricas para identificar tendências. Se o P99 começa a aumentar gradualmente ao longo de semanas, isso pode indicar que o sistema está entrando em um estado de degradação, mesmo que a média ainda pareça estável. Essa análise histórica é fundamental para prever problemas e implementar melhorias antes que eles se tornem visíveis para os usuários.
Adicionando OpenTelemetry ao .NET
Para capturar métricas detalhadas e realizar traces que ajudam a monitorar o tempo de resposta de forma granular, o OpenTelemetry é uma ferramenta indispensável. Sua implementação no .NET é relativamente simples, mas exige atenção aos detalhes para que todas as métricas relevantes sejam capturadas corretamente.
á abordamos este tema em profundidade no artigo “Observabilidade em Aplicações .NET com OpenTelemetry“, onde você encontrará um passo a passo detalhado para configurar e instrumentar sua aplicação. Lá, discutimos como configurar os exporters, como o Prometheus, e como integrar bibliotecas que ajudam a capturar tempos de resposta, métricas HTTP e outras informações essenciais.
Explorando as métricas do Prometheus para Response Time
O Prometheus é uma ferramenta poderosa para capturar e armazenar métricas, e quando integrado ao OpenTelemetry, fornece uma base sólida para monitorar o response time. Ele utiliza o conceito de histogramas e buckets para representar tempos de resposta, permitindo análises detalhadas de distribuição e percentis.
Como o Prometheus registra tempos de resposta
No Prometheus, os tempos de resposta são geralmente expostos como métricas de histograma, organizadas em buckets que agrupam os valores em intervalos predefinidos. Um histograma é composto por:
- Buckets: Intervalos que representam os tempos de resposta (por exemplo, 0.1s, 0.2s, 0.5s, etc.).
- Contadores cumulativos: O número de requisições que se enquadram em cada bucket.
- Soma total: O tempo acumulado de todas as requisições monitoradas.
Por exemplo, uma métrica de histograma comum é http_server_request_duration_seconds, que mede os tempos de resposta em segundos. Seus buckets podem ser configurados para capturar tempos de 0.1s, 0.2s, 0.5s, 1s, e assim por diante.
http_server_request_duration_seconds_bucket{le="0.1"} 45
http_server_request_duration_seconds_bucket{le="0.2"} 89
http_server_request_duration_seconds_bucket{le="0.5"} 120
http_server_request_duration_seconds_bucket{le="1"} 150
http_server_request_duration_seconds_bucket{le="+Inf"} 200Aqui:
- O bucket
le="0.1"indica que 45 requisições tiveram tempos de resposta inferiores ou iguais a 0.1s. - O bucket
le="1"mostra que 150 requisições foram concluídas com tempos de até 1s. - O bucket
le="+Inf"é o total de requisições, sem limite de tempo.
Esses dados formam a base para calcular percentis como o P99, que destacam as requisições mais lentas e seus tempos de resposta.
Calculando Percentis no Prometheus
O Prometheus permite calcular percentis usando a função histogram_quantile. Essa função analisa os dados do histograma e calcula o tempo correspondente a um percentil específico. Por exemplo:
histogram_quantile(0.99, sum(rate(http_server_request_duration_seconds_bucket[5m])) by (le))0.99: Representa o percentil P99.rate(...[5m]): Calcula a taxa de requisições por bucket nos últimos 5 minutos.sum(...) by (le): Agrupa os dados por limite de bucket para análise.
Esse query retornará o tempo de resposta no qual 99% das requisições foram concluídas, destacando os momentos mais críticos.
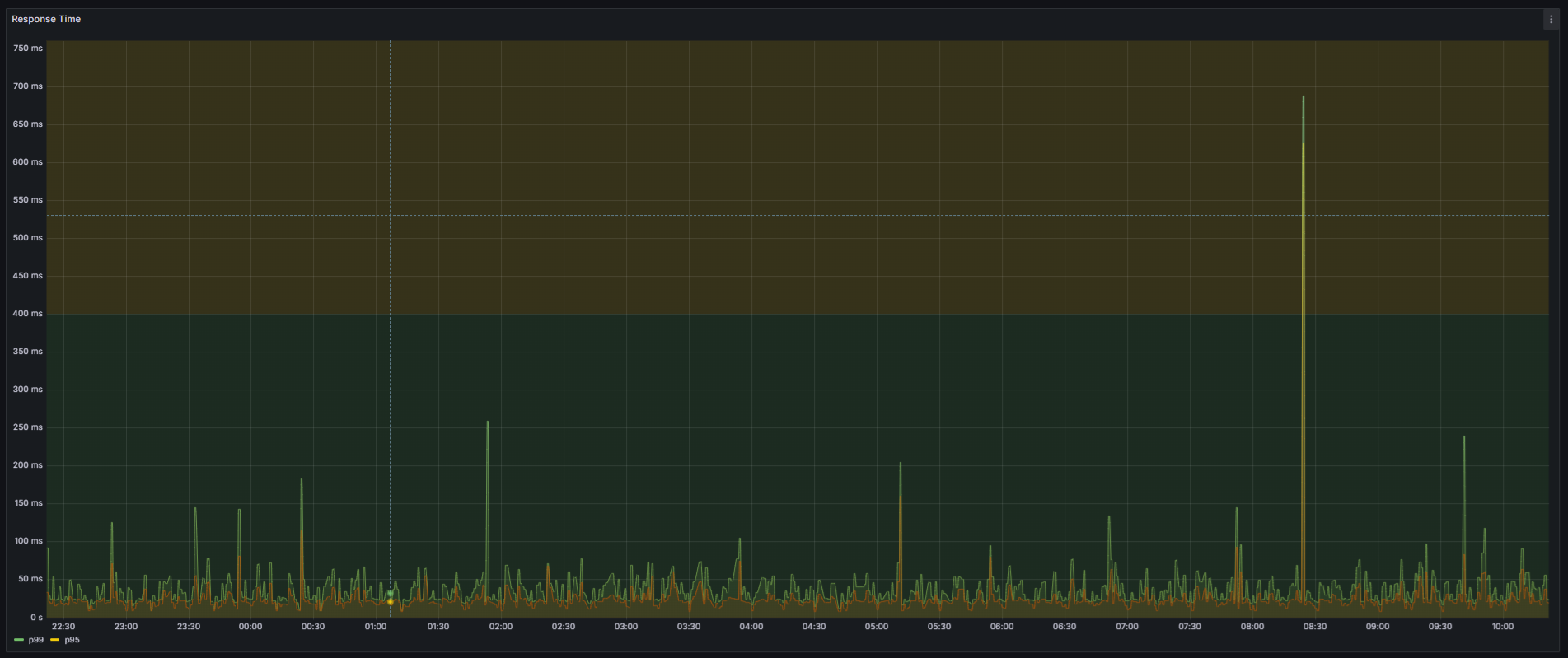
Visualizando o Response Time no Grafana
Com os dados do Prometheus, é possível criar dashboards no Grafana para acompanhar o P99, o P95 e outros percentis em tempo real. Um exemplo de painel pode incluir:
- Um gráfico de linhas mostrando o P99 ao longo do tempo.
- Um histograma exibindo a distribuição dos tempos de resposta por bucket.
Ao visualizar essas métricas, é possível identificar rapidamente aumentos no P99, que geralmente indicam gargalos ou picos de carga.
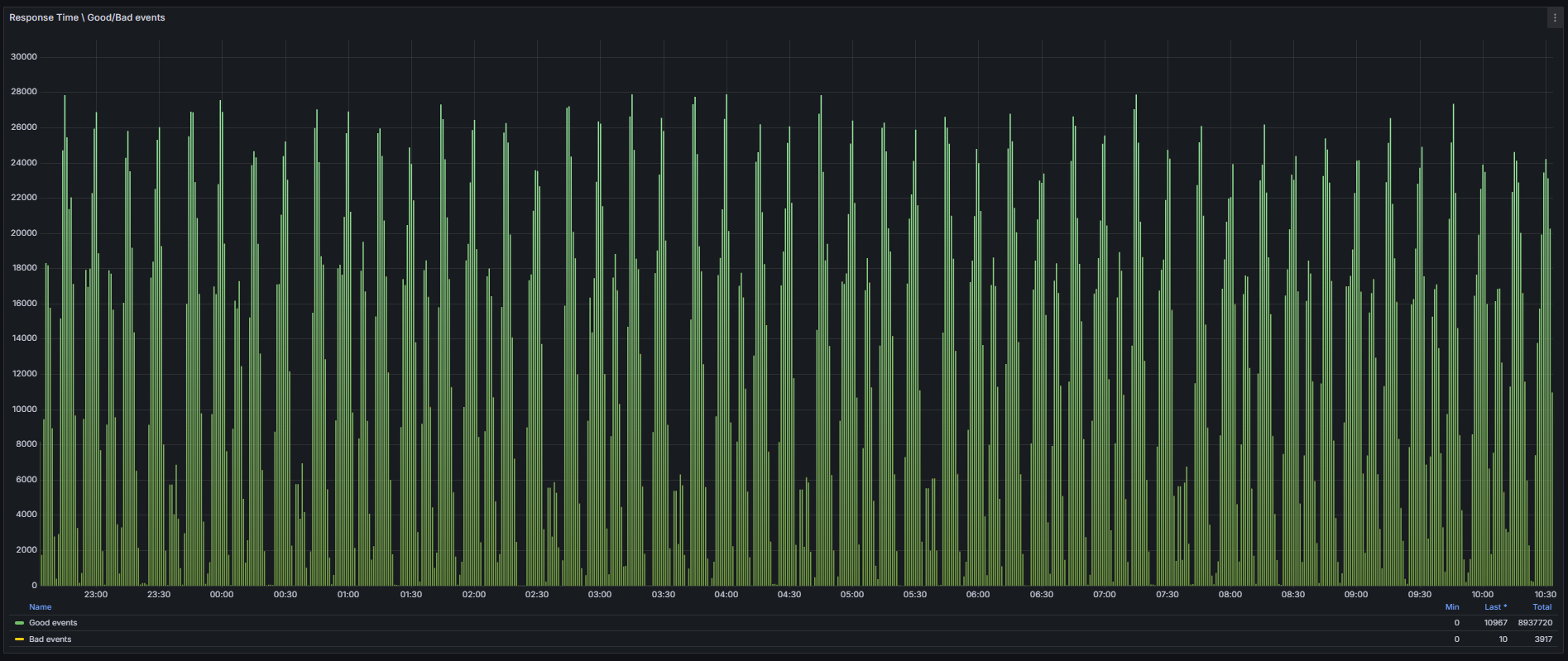
Monitorando Good Requests e Bad Requests
Para manter a qualidade do serviço e garantir a satisfação do usuário, é crucial monitorar o desempenho do sistema, categorizando requisições como aceitáveis (good requests) ou problemáticas (bad requests). Este método possibilita uma análise clara da saúde da aplicação e facilita a identificação de problemas que podem impactar diretamente a experiência do cliente.
O conceito de good e bad requests é baseado na comparação dos tempos de resposta com um limiar (threshold) definido, que neste caso é de 400ms. Requisições com tempos inferiores ao limite são classificadas como good events, enquanto aquelas que ultrapassam são consideradas bad events. O gráfico fornecido ilustra claramente a proporção entre essas categorias ao longo do tempo, permitindo uma análise detalhada.
Definindo Good e Bad Requests
Good requests, são as requisições cujo tempo de resposta está dentro do limite aceitável de 400ms. Elas representam operações que foram executadas de forma rápida e dentro das expectativas dos usuários.
sum(
rate(
http_server_request_duration_seconds_bucket{exported_job="service_name", le="0.4"}[$__rate_interval]
)
)Essa query soma as taxas de requisições dentro do bucket de 400ms, representando o total de good requests em um intervalo de tempo.
Bad requests, são as requisições cujo tempo de resposta excedeu o limite de 400ms. Elas indicam gargalos, atrasos ou problemas em algum ponto do sistema.
sum(
rate(
http_server_request_duration_seconds_count{exported_job="service_name"}[$__rate_interval]
)
) - sum(
rate(
http_server_request_duration_seconds_bucket{exported_job="service_name", le="0.4"}[$__rate_interval]
)
)Essa query calcula o total de requisições e subtrai o número de good requests, resultando na quantidade de bad requests. A imagem abaixo exibe a proporção de good requests (em verde) e bad requests (em amarelo) ao longo do tempo.
Como investigar e corrigir tempos de resposta elevados?
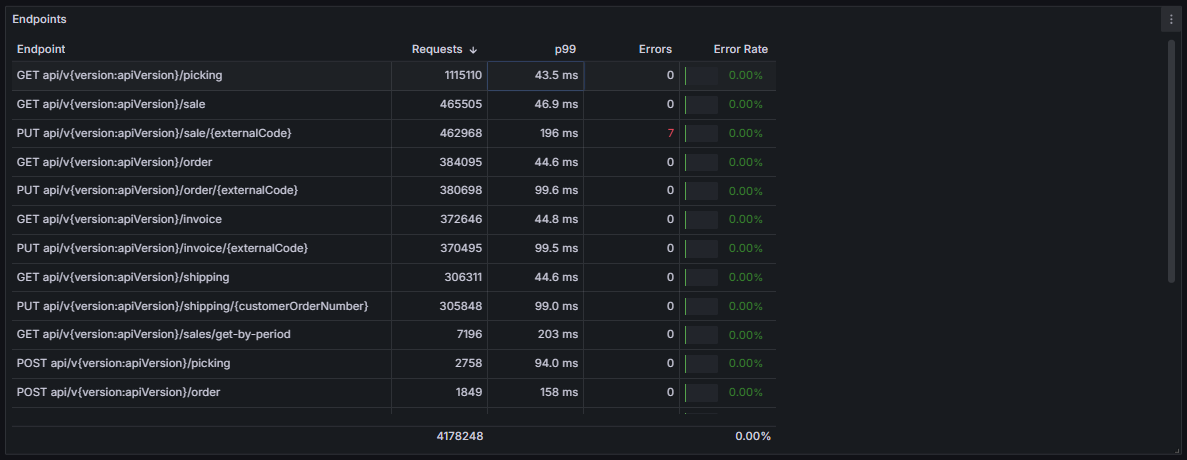
A investigação de tempos de resposta elevados começa com uma análise detalhada dos dados capturados por ferramentas como Prometheus e Grafana. Monitorar apenas o comportamento geral do sistema não é suficiente; é necessário desagrupar os dados por endpoint, como mostrado na tabela fornecida, para compreender os pontos específicos que estão contribuindo para gargalos. Cada endpoint pode representar uma etapa de uma jornada, como checkout, busca de produtos ou processamento de pedidos. Essa segmentação é importante para identificar onde os problemas estão e agir diretamente nos pontos críticos.
Segmentar endpoints: o primeiro passo para uma análise eficiente
A imagem abaixo ilustra como desagrupar os endpoints pode transformar uma análise geral em um diagnóstico preciso. Na tabela, cada endpoint está detalhado com o número de requisições, percentil P99, erros e taxa de erro. Isso permite identificar rapidamente os pontos com maior tráfego ou maior latência. Por exemplo, o endpoint PUT api/{version}/sale/{externalCode} apresenta um P99 de 196ms, significativamente mais alto que outros endpoints no mesmo sistema, e registra 7 erros.
Essa granularidade possibilita análises por jornada, agrupando endpoints relacionados que compõem fluxos específicos de interação do usuário. Um exemplo seria analisar a jornada de compra, que pode incluir endpoints como /sale, /order e /invoice. Esse agrupamento permite identificar gargalos que afetam diretamente uma experiência completa, em vez de apenas eventos isolados.
Conclusão
Monitorar o tempo de resposta de uma aplicação exige mais do que métricas superficiais ou análises generalizadas. Ao longo deste artigo, vimos como utilizar ferramentas como OpenTelemetry, Prometheus e Grafana para capturar dados detalhados, analisar percentis como o P99 e categorizar requisições em good requests e bad requests. Essas práticas permitem que as equipes compreendam com clareza os gargalos que afetam o desempenho e tomem decisões informadas para garantir a consistência da experiência do usuário.
O desmembramento de métricas por endpoint, aliado à possibilidade de agrupá-los em jornadas completas, transforma dados brutos em insights estratégicos. Essa abordagem não apenas permite detectar problemas antes que eles escalem, mas também ajuda a alinhar a performance técnica aos objetivos de negócio.
Escolher as ferramentas certas e implementar uma estratégia bem estruturada de monitoramento são passos decisivos para criar sistemas confiáveis, ágeis e adaptáveis a cenários de alta demanda. Os conceitos apresentados aqui oferecem uma base sólida para equipes que buscam melhorar a visibilidade de seus sistemas e reduzir impactos negativos para os usuários e para os negócios.
FAQ: Perguntas Frequentes
1. O que é o percentil 99 e por que ele é mais importante que a média?
O percentil 99, ou P99 é o tempo de resposta no qual 99% das requisições são atendidas. Ele é mais importante que a média porque destaca os piores cenários de latência, enquanto a média pode mascarar esses problemas. O P99 é essencial para identificar gargalos que impactam diretamente os usuários.
2. Por que devo segmentar os endpoints ao invés de analisar o tempo de resposta da aplicação como um todo?
A segmentação por endpoints permite identificar pontos específicos do sistema que estão enfrentando problemas, como latência alta ou taxas de erro. Analisar a aplicação de forma global pode ocultar gargalos em partes críticas, como o checkout de um e-commerce.
3. Como configurar métricas de good requests e bad requests no Prometheus?
Para monitorar good requests, você pode usar a query:
sum(rate(http_server_request_duration_seconds_bucket{le=”0.4″}[$__rate_interval]))
Para bad requests, subtraia o total de requisições pelas good requests:
sum(rate(http_server_request_duration_seconds_count[$__rate_interval])) – sum(rate(http_server_request_duration_seconds_bucket{le=”0.4″}[$__rate_interval]))
4. Quais ferramentas devo usar para rastrear gargalos no tempo de resposta?
OpenTelemetry é ideal para tracing, fornecendo detalhes sobre o fluxo de requisições. Prometheus coleta métricas precisas e Grafana permite criar dashboards para visualização. A combinação dessas ferramentas oferece visibilidade abrangente.
5. O que são jornadas de usuário e como elas ajudam na análise do desempenho?
Jornadas de usuário são conjuntos de endpoints que representam um fluxo completo, como o processo de compra em um e-commerce. Agrupar endpoints dessa forma ajuda a identificar como problemas em um ponto específico podem impactar a experiência geral do cliente e os resultados do negócio.

