


Quatro Sinais de Ouro – Aprendas as quatro principais métricas da SRE
Começar pelos quatro sinais de ouro permite criar métricas que ajudam na confiabilidade do software. Frequentemente é percebida uma queda de braços entre times de engenharia de produtos e operações. De um lado, times de produtos, querendo colocar sua proposta de valor em produção. Do outro lado operações, querendo maximizar a estabilidade em produção.
Quais são as quatro métricas de ouro?
Dado o cenário, surgem os quatro sinais de ouro, latência, tráfego, erros e saturação que é início para medir a confiabilidade do software, plataforma ou serviço. Com propósitos diferentes, cada métrica responde a questões específicas sobre o quão confiável é seu software ou serviço.
O intervalo entre uma ação e o retorno dessa ação é a Latência
Latência é o intervalo entre uma ação e uma reação. Ao clicar em um botão, ocorrerá uma chamada ao servidor, algo será processado com um retorno. Assim sendo, o tempo entra ação e reação é a latência, como dito anteriormente. Entretanto, nesse meio há a latência da internet, que deve ser desprezada.
Dessa forma, pelas lentes dos quatro sinais de ouro, para a latência, recomenda-se uma visão daquilo o servidor processou. Garantir aquilo que é processado, servidor, é o ponto inicial para o entendimento e análise da latência.
A fim de trazer ainda mais clareza e considerando que os status de retorno estejam certos, seguindo a RFC 2616, algumas situações podem ocorrer em uma requisição:
- Em um curto período de tempo, milissegundos, temos código de retorno 200
- Embora com tempo degradado, ou seja, um tempo maior que, temos o código de retorno 200
- A falha acontece rapidamente com um código de retorno 500
- A requisição demora muito tempo com um código de retorno 500
Erros lentos prejudicam a confiabilidade do software
Erros lentos são mais prejudiciais, uma vez que exigem mais recurso computacional se comparado com o errar rápido. A maneira recomendada de identificar essa lentidão é utilizando o modelo estatístico percentil.
Por exemplo, posso perguntar qual é a latência para serviços que responderam com código 200? Utilizando percentil, a resposta, pode ser 95% das minhas requisições ocorrem com menos de 100 milissegundos.
Para quem utiliza o Prometheus como banco de dados para monitoramento a métrica utilizada é http_request_duration_seconds_bucket com uma função histogram_quantile.
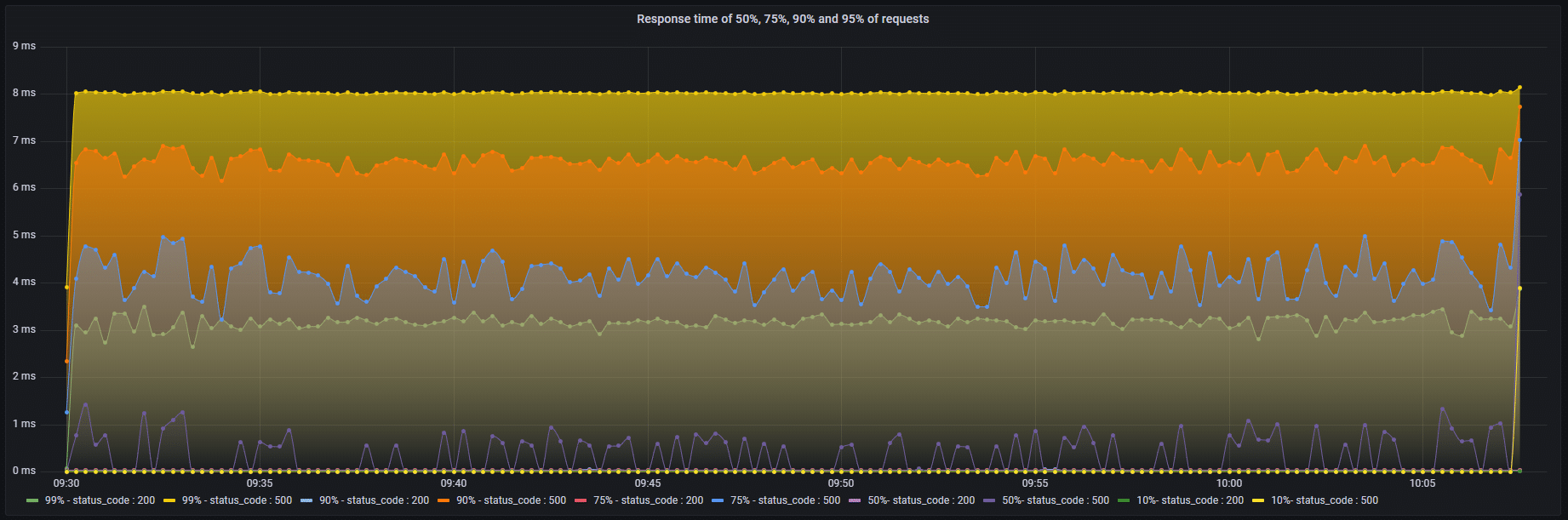
Tráfego e a quantidade de erros é o termômetro para confiabilidade
Assim como latência, ter a quantidade de erros e o tráfego medidos trará aos operadores clareza do estado atual do serviço. O foco é saber quantas requisições estão acontecendo no momento e quantas estão com erros.
Esses dois indicadores ajudam a saber sobre:
- Se seu sistema está sofrendo com alta demanda de acessos
- Em conjunto com a latência e saturação você compara o comportamento do serviço em caso de lentidão
- Quantas requisições estão apresentando erros
Do mesmo modo, outras análises devem ser feitas para compreender melhor o estado do serviço. Tudo depende do cenário que está passando no momento da crise.
No Prometheus utilize as métricas http_requests_received_total e http_requests_in_progress. Em conjunto elas darão o total de requisições boas em andamento. Do mesmo modo você pode filtrar para descobrir a quantidade de requisições com erro, utilize o filtro “code=5xx”.
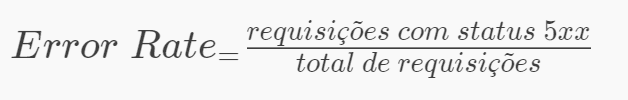
Error rate bem definido, assim como a disponibilidade ajudam a criar alertas para saber o quão disponível determinando o estado do serviço. Se alinhados à um SLO, Service Level Objectives, trará clareza no aspecto de experiência do cliente.
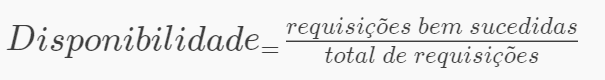
Recursos computacionais como CPU, memória, i/o e network são medidos pela Saturação
Não só latência, erros e tráfego, ao falarmos de saturação nos quatro sinais de ouro, estamos falando de recursos computacionais. Eventualmente, se um recurso computacional como memória está comprometido, as aplicações começam a ficar indisponíveis.
Alguns tipos de linguagens de programação como .NET, pelo Prometheus, possibilita diversos “contadores” para medir a saturação de um sistema.
JIT
- dotnet_jit_cpu_ratio
- dotnet_jit_method_total
- dotnet_jit_method_seconds_total
- dotnet_gc_allocated_bytes_total
- dotnet_gc_collection_count_total
- dotnet_gc_memory_total_available_bytes
- dotnet_gc_pause_ratio
- dotnet_gc_heap_size_bytes
Bloqueios
- dotnet_contention_total
Threads
- dotnet_threadpool_queue_length
- dotnet_threadpool_timer_count
Em resumo, construir sistemas confiáveis dependem de métricas eficazes.

