


Monitorar métricas de runtime do .NET é essencial para manter aplicações performáticas em produção. O runtime expõe dezenas de métricas através da API System.Diagnostics.Metrics, cobrindo Garbage Collector, Thread Pool, JIT, exceções e uso de recursos. Ferramentas como Datadog, Prometheus e Azure Monitor conseguem coletar e visualizar essas métricas automaticamente, permitindo identificar gargalos antes que afetem usuários.
Insights
- GC Pause Time é o vilão silencioso: Pausas frequentes do Garbage Collector podem causar latência perceptível ao usuário, mesmo com CPU e memória aparentemente saudáveis.
- Thread Pool Queue Length revela saturação antes do colapso: Quando a fila de work items cresce consistentemente, sua aplicação está prestes a sofrer degradação de performance.
- First Chance Exceptions nem sempre são problemas: Exceções capturadas em try/catch também são contabilizadas. O padrão de crescimento importa mais que o número absoluto.
- LOH e POH são coletados apenas na Gen2: Objetos grandes (>85KB) e objetos pinados têm custo de coleta maior. Monitore-os separadamente.
- Contention Count alto indica locks mal projetados: Contenção de locks é sintoma de código que não escala. Considere estruturas lock-free ou particionamento.
As métricas mais críticas para análise são: GC pause time (impacto direto na latência), thread pool queue length (saturação de processamento), heap size por geração (pressão de memória) e contention count (problemas de concorrência). Entender o que cada métrica representa e como interpretar seus valores transforma dados brutos em decisões de otimização concretas.
Por que monitorar métricas de runtime?
CPU e memória são métricas de infraestrutura. Elas dizem que algo está errado, mas não o quê. Métricas de runtime revelam o comportamento interno da aplicação: como o Garbage Collector está operando, se há contenção de threads, quantas exceções estão sendo lançadas.
Uma aplicação pode ter CPU em 30% e ainda assim apresentar latência alta por pausas excessivas do GC. Pode ter memória disponível e sofrer com thread pool starvation. Sem métricas de runtime, você está diagnosticando no escuro.
Anatomia das métricas de runtime do .NET
O .NET organiza métricas de runtime em categorias distintas. Vamos analisar cada uma:
1. Métricas de Garbage Collector
O GC é responsável por liberar memória automaticamente. Suas métricas são as mais críticas para performance:
| Métrica | Tipo | O que mede |
|---|---|---|
dotnet.gc.collections | Counter | Número de coletas por geração (gen0, gen1, gen2) |
dotnet.gc.heap.total_allocated | Counter | Total de bytes alocados desde o início |
dotnet.gc.pause.time | Counter | Tempo total em pausas de GC |
dotnet.gc.last_collection.heap.size | Gauge | Tamanho do heap por geração após última coleta |
dotnet.gc.last_collection.heap.fragmentation.size | Gauge | Fragmentação do heap |
Como interpretar:
- Gen0 collections altas, Gen2 baixas: Comportamento saudável. Objetos de vida curta são coletados rapidamente.
- Gen2 collections frequentes: Problema. Objetos estão sobrevivendo muito tempo ou há muitas alocações no Large Object Heap.
- GC pause time crescendo: A aplicação está pausando cada vez mais para coletas. Impacta diretamente a latência.
- Fragmentação alta: Memória está fragmentada. Pode causar alocações mais lentas e OutOfMemoryException mesmo com memória disponível.
2. Métricas de Thread Pool
O Thread Pool gerencia threads para operações assíncronas. Saturação aqui causa lentidão generalizada:
| Métrica | Tipo | O que mede |
|---|---|---|
dotnet.thread_pool.thread.count | Gauge | Threads atualmente no pool |
dotnet.thread_pool.queue.length | Gauge | Work items aguardando processamento |
dotnet.thread_pool.work_item.count | Counter | Work items completados |
Como interpretar:
- Queue length consistentemente > 0: Work items estão acumulando. O pool não consegue processar na velocidade que chegam.
- Thread count crescendo rapidamente: O runtime está criando threads para compensar demanda. Pode indicar bloqueio síncrono em código async.
- Thread count no máximo e queue crescendo: Thread pool starvation. A aplicação vai degradar severamente.
3. Métricas de Exceções
Exceções têm custo de performance e indicam problemas na lógica:
| Métrica | Tipo | O que mede |
|---|---|---|
dotnet.exceptions | Counter | Total de exceções lançadas, por tipo |
Como interpretar:
- Crescimento constante de um tipo específico: Investigue a causa raiz.
- OperationCanceledException alta: Normal em aplicações com cancelamento. Não necessariamente um problema.
- NullReferenceException ou ArgumentException: Bugs no código. Corrija imediatamente.
4. Métricas de Contenção
Contenção ocorre quando múltiplas threads tentam adquirir o mesmo lock:
| Métrica | Tipo | O que mede |
|---|---|---|
dotnet.monitor.lock_contentions | Counter | Vezes que uma thread esperou por um lock |
Como interpretar:
- Contention count baixo e estável: Saudável.
- Contention count crescendo com carga: Locks estão se tornando gargalo. Considere redesenhar para estruturas concorrentes ou lock-free.
Coletando Métricas com OpenTelemetry
A forma moderna de coletar métricas é via OpenTelemetry. O código abaixo configura coleta completa de métricas de runtime:
using OpenTelemetry.Metrics;
using OpenTelemetry.Resources;
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddOpenTelemetry()
.ConfigureResource(resource => resource
.AddService(serviceName: "minha-api"))
.WithMetrics(metrics =>
{
// Métricas de runtime do .NET
metrics.AddRuntimeInstrumentation();
// Métricas do ASP.NET Core
metrics.AddAspNetCoreInstrumentation();
// Métricas de HttpClient
metrics.AddHttpClientInstrumentation();
// Exportar para console (desenvolvimento)
metrics.AddConsoleExporter();
// Exportar para OTLP (produção)
metrics.AddOtlpExporter(options =>
{
options.Endpoint = new Uri("http://localhost:4317");
});
});
var app = builder.Build();
app.MapGet("/", () => "Hello World");
app.Run();Pacotes NuGet necessários:
<PackageReference Include="OpenTelemetry.Extensions.Hosting" Version="1.10.0" />
<PackageReference Include="OpenTelemetry.Instrumentation.AspNetCore" Version="1.10.1" />
<PackageReference Include="OpenTelemetry.Instrumentation.Http" Version="1.10.0" />
<PackageReference Include="OpenTelemetry.Instrumentation.Runtime" Version="1.10.0" />
<PackageReference Include="OpenTelemetry.Exporter.Console" Version="1.10.0" />
<PackageReference Include="OpenTelemetry.Exporter.OpenTelemetryProtocol" Version="1.10.0" />Coletando Métricas com Datadog
O Datadog coleta métricas de runtime automaticamente quando você habilita o tracer:
// Program.cs - Configuração mínima
var builder = WebApplication.CreateBuilder(args);
// O Datadog tracer coleta métricas automaticamente
// Configure via variáveis de ambiente
var app = builder.Build();
app.MapGet("/", () => "Hello World");
app.Run();Variáveis de ambiente necessárias:
# Habilitar métricas de runtime
DD_RUNTIME_METRICS_ENABLED=true
# Configuração do tracer
DD_ENV=production
DD_SERVICE=minha-api
DD_VERSION=1.0.0
# Endpoint do agent
DD_AGENT_HOST=localhost
DD_TRACE_AGENT_PORT=8126Dockerfile com Datadog:
FROM mcr.microsoft.com/dotnet/aspnet:9.0 AS base
WORKDIR /app
# Instalar o tracer Datadog
RUN apt-get update && apt-get install -y curl
RUN curl -LO https://github.com/DataDog/dd-trace-dotnet/releases/latest/download/datadog-dotnet-apm_amd64.deb
RUN dpkg -i datadog-dotnet-apm_amd64.deb
RUN rm datadog-dotnet-apm_amd64.deb
# Configurar variáveis de ambiente
ENV CORECLR_ENABLE_PROFILING=1
ENV CORECLR_PROFILER={846F5F1C-F9AE-4B07-969E-05C26BC060D8}
ENV CORECLR_PROFILER_PATH=/opt/datadog/Datadog.Trace.ClrProfiler.Native.so
ENV DD_DOTNET_TRACER_HOME=/opt/datadog
ENV DD_RUNTIME_METRICS_ENABLED=true
FROM mcr.microsoft.com/dotnet/sdk:9.0 AS build
WORKDIR /src
COPY . .
RUN dotnet publish -c Release -o /app/publish
FROM base AS final
WORKDIR /app
COPY --from=build /app/publish .
ENTRYPOINT ["dotnet", "MinhaApi.dll"]Criando métricas customizadas
Além das métricas de runtime, você pode criar métricas específicas do seu domínio:
using System.Diagnostics.Metrics;
public class PedidoMetrics
{
private readonly Counter<long> _pedidosCriados;
private readonly Counter<long> _pedidosCancelados;
private readonly Histogram<double> _tempoProcesamento;
private readonly ObservableGauge<int> _pedidosPendentes;
private int _pendentes = 0;
public PedidoMetrics(IMeterFactory meterFactory)
{
var meter = meterFactory.Create("MinhaEmpresa.Pedidos");
_pedidosCriados = meter.CreateCounter<long>(
name: "pedidos.criados",
unit: "{pedido}",
description: "Número de pedidos criados");
_pedidosCancelados = meter.CreateCounter<long>(
name: "pedidos.cancelados",
unit: "{pedido}",
description: "Número de pedidos cancelados");
_tempoProcesamento = meter.CreateHistogram<double>(
name: "pedidos.tempo_processamento",
unit: "ms",
description: "Tempo para processar um pedido");
_pedidosPendentes = meter.CreateObservableGauge(
name: "pedidos.pendentes",
observeValue: () => _pendentes,
unit: "{pedido}",
description: "Pedidos aguardando processamento");
}
public void RegistrarPedidoCriado(string tipo)
{
_pedidosCriados.Add(1, new KeyValuePair<string, object?>("tipo", tipo));
Interlocked.Increment(ref _pendentes);
}
public void RegistrarPedidoProcessado(double tempoMs)
{
_tempoProcesamento.Record(tempoMs);
Interlocked.Decrement(ref _pendentes);
}
public void RegistrarPedidoCancelado(string motivo)
{
_pedidosCancelados.Add(1, new KeyValuePair<string, object?>("motivo", motivo));
Interlocked.Decrement(ref _pendentes);
}
}
// Registro no DI
builder.Services.AddSingleton<PedidoMetrics>();
// Uso em um endpoint
app.MapPost("/pedidos", (PedidoMetrics metrics) =>
{
var sw = Stopwatch.StartNew();
metrics.RegistrarPedidoCriado("online");
// Simular processamento
Thread.Sleep(100);
metrics.RegistrarPedidoProcessado(sw.ElapsedMilliseconds);
return Results.Created("/pedidos/123", new { id = 123 });
});
Dashboard do Datadog para referência
Baseado na imagem de referência do Datadog, estas são as métricas essenciais para um dashboard de runtime .NET:
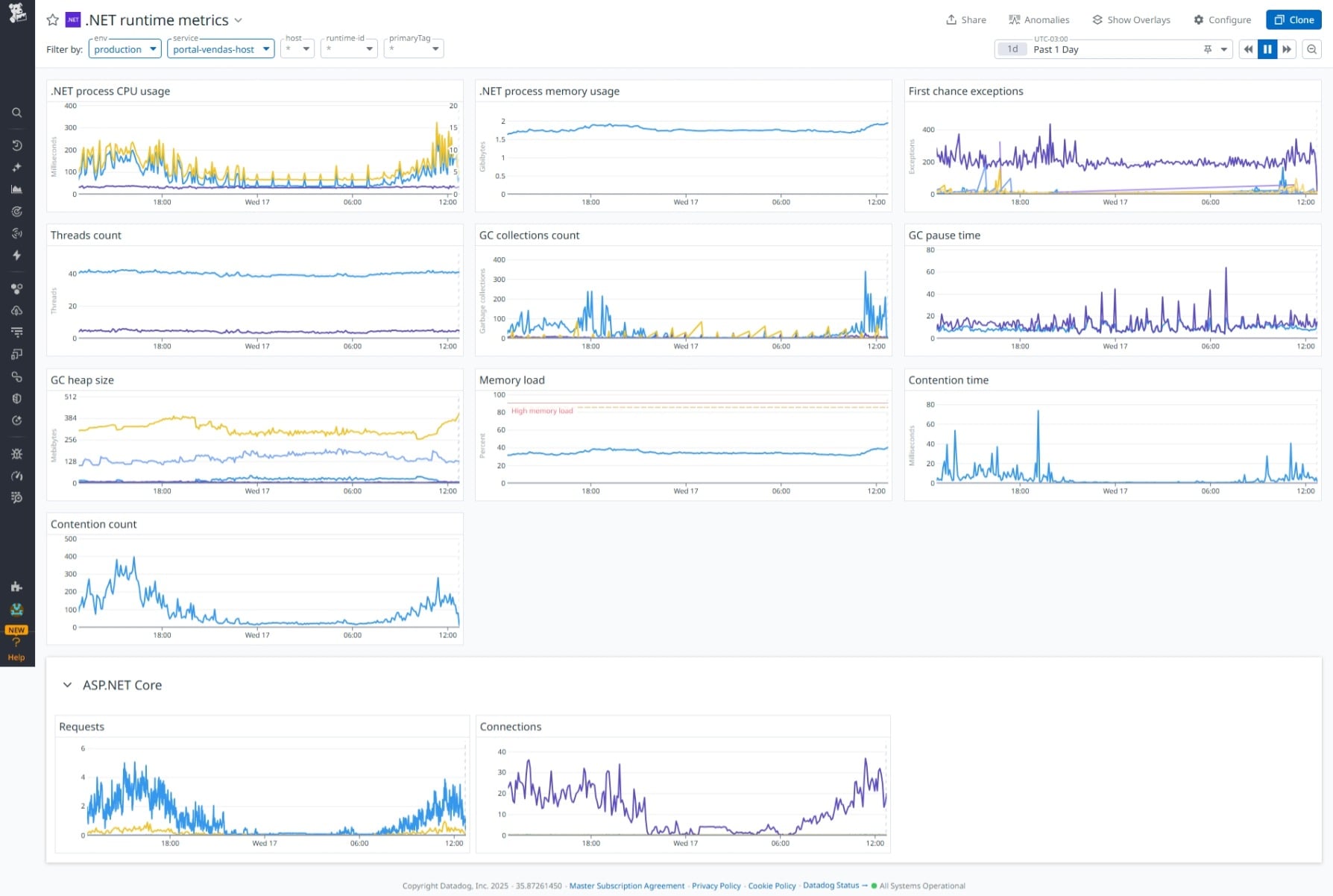
Painel 1 – Recursos do Processo:
- .NET process CPU usage (user vs system)
- .NET process memory usage (working set)
- Memory load percentage
Painel 2 – Garbage Collector:
- GC collections count (por geração)
- GC heap size (por geração + LOH + POH)
- GC pause time
Painel 3 – Threads e Concorrência:
- Thread pool thread count
- Thread pool queue length
- Contention count
- Contention time
Painel 4 – Exceções e Erros:
- First chance exceptions (por tipo)
- Unhandled exceptions
Painel 5 – ASP.NET Core (se aplicável):
- Requests per second
- Active connections
- Request duration (p50, p95, p99)
Alertas Recomendados
Configure alertas para estas condições:
| Condição | Severidade | Ação |
|---|---|---|
| GC pause time > 200ms em 5min | Warning | Investigar alocações |
| GC pause time > 500ms em 5min | Critical | Escalar imediatamente |
| Thread pool queue > 100 por 1min | Warning | Verificar bloqueios |
| Thread pool queue > 500 por 1min | Critical | Adicionar capacidade |
| Gen2 collections > 10/min | Warning | Revisar ciclo de vida de objetos |
| Contention count crescendo 50%/hora | Warning | Revisar locks |
| Memory load > 80% | Warning | Avaliar memory leak |
| Memory load > 95% | Critical | Risco de OOM |
Diagnóstico
Latência Alta
├── GC pause time alto?
│ ├── Sim → Muitas alocações ou objetos grandes
│ │ ├── Gen2 collections frequentes? → Objetos vivendo muito
│ │ └── LOH size grande? → Alocações >85KB
│ └── Não → Continuar investigação
├── Thread pool queue length alto?
│ ├── Sim → Thread pool starvation
│ │ └── Há .Wait() ou .Result em código async? → Remover bloqueios
│ └── Não → Continuar investigação
├── Contention count alto?
│ ├── Sim → Locks são gargalo
│ │ └── Usar ConcurrentDictionary, Interlocked, etc.
│ └── Não → Problema pode ser externo (DB, rede)
Exemplo Completo de uma API com Observabilidade
using System.Diagnostics;
using System.Diagnostics.Metrics;
using OpenTelemetry.Metrics;
using OpenTelemetry.Resources;
using OpenTelemetry.Trace;
var builder = WebApplication.CreateBuilder(args);
// Configurar OpenTelemetry
builder.Services.AddOpenTelemetry()
.ConfigureResource(resource => resource
.AddService(
serviceName: "pedidos-api",
serviceVersion: "1.0.0"))
.WithMetrics(metrics =>
{
metrics
.AddRuntimeInstrumentation()
.AddAspNetCoreInstrumentation()
.AddHttpClientInstrumentation()
.AddMeter("MinhaEmpresa.Pedidos")
.AddOtlpExporter();
})
.WithTracing(tracing =>
{
tracing
.AddAspNetCoreInstrumentation()
.AddHttpClientInstrumentation()
.AddOtlpExporter();
});
// Registrar métricas customizadas
builder.Services.AddSingleton<PedidoMetrics>();
var app = builder.Build();
// Health check com métricas
app.MapGet("/health", () =>
{
var gcInfo = GC.GetGCMemoryInfo();
var threadInfo = ThreadPool.ThreadCount;
return Results.Ok(new
{
status = "healthy",
gc = new
{
heapSizeBytes = gcInfo.HeapSizeBytes,
memoryLoadPercent = gcInfo.MemoryLoadBytes * 100.0 / gcInfo.TotalAvailableMemoryBytes,
gen0Collections = GC.CollectionCount(0),
gen1Collections = GC.CollectionCount(1),
gen2Collections = GC.CollectionCount(2),
pauseTimeMs = GC.GetTotalPauseDuration().TotalMilliseconds
},
threads = new
{
threadPoolThreads = threadInfo,
pendingWorkItems = ThreadPool.PendingWorkItemCount
}
});
});
app.MapGet("/", () => "Pedidos API v1.0");
app.Run();Conclusão
Métricas de runtime são a diferença entre reagir a problemas e preveni-los. Com as ferramentas certas e o conhecimento de como interpretar cada métrica, você transforma dados em ações concretas de otimização.
Comece habilitando a coleta de métricas em uma aplicação. Observe o comportamento normal por alguns dias. Depois, configure alertas para desvios. Em poucas semanas, você terá visibilidade completa do comportamento interno das suas aplicações .NET.
FAQ: Perguntas Frequentes
1. Qual a diferença entre GC pause time e GC collection count?
GC collection count indica quantas vezes o Garbage Collector executou. GC pause time indica quanto tempo a aplicação ficou pausada durante essas coletas. Você pode ter muitas coletas rápidas (bom) ou poucas coletas lentas (ruim). O pause time é mais relevante para latência.
2. Por que minha aplicação tem alto contention count mesmo com poucos usuários?
Contention ocorre quando threads disputam o mesmo lock. Pode acontecer com poucos usuários se houver um lock global (singleton mal implementado, cache com lock exclusivo, logging síncrono). Use o profiler para identificar qual lock está causando contenção.
3. O que significa thread pool starvation e como resolver?
Thread pool starvation ocorre quando todos os threads estão ocupados e novos work items ficam na fila. A causa mais comum é código que bloqueia threads async com .Wait() ou .Result. A solução é usar await consistentemente e evitar bloqueios síncronos em código assíncrono.
4. Devo me preocupar com First Chance Exceptions?
Depende. First Chance Exceptions incluem exceções tratadas em try/catch, o que é normal. Preocupe-se quando: (1) o número cresce sem motivo aparente, (2) há tipos de exceção inesperados como NullReferenceException, (3) exceções ocorrem em hot paths afetando performance.
5. Como saber se meu heap size está saudável?
Compare o heap size com a memória disponível e observe a tendência. Um heap que cresce constantemente indica possível memory leak. O ideal é que o heap oscile (cresce com uso, diminui após GC) em torno de um valor estável. Use o memory load percentage como indicador: abaixo de 70% geralmente é saudável.

